
Share
What is Speech Recognition?
Speech Recognition (SR), also known as Automatic Speech Recognition (ASR), is a system for processing captured audio and converting the sound to text. This is the first step to let users control devices and systems by speaking instead of using conventional tools such as keystrokes or buttons.
Why Speech Recognition?
Phone conversations are still the main interaction between people and businesses, but manual conversation analysis requires a vast amount of time and effort. Today, this process is easier with speech analysis software that leverages automatic speech recognition (ASR) technology. ASR assists in the automatic transcription of recordings (speech-to-text), and it takes much less effort and time.
SR technology is the core technology behind Conversational AI solutions such as virtual assistants and voice-enabled IVR systems. Companies of all sizes from different industries are now using Conversational solutions powered by SR technology to contribute to the lives of their customers and employees positively.
What Do We Work on?
Recently, speech technologies have been moving from deep neural network-based Hybrid modeling to end-to-end (E2E) modeling. While E2E models achieve state-of-the-art results in most benchmarks in terms of SR accuracy, Hybrid models are still used in a large proportion of commercial SR systems.
As SESTEK, we are an R&D center with 100+ engineers, and we closely follow state-of-the-art technologies and upgrade our solutions to produce the best solutions for our customers.
For this reason, we performed a study to train our models with new technology, compared these versions and measured their performances.
Difference Between Hybrid and E2E
Traditional Hybrid speech recognition systems work by independently training separate modules such as the acoustic model, language model, and phonetic dictionary and combining these modules during decoding of the input audio recording. On the other hand, E2E has a much simpler training pipeline decoding process through a single neural network. This reduces the training and decoding time and allows joint optimization with downstream processing, such as natural language understanding (NLU).
As for the disadvantages of Hybrid systems, the optimal state of each module does not guarantee that the combined system used during deciphering is also in an optimal state. The training of each module may require different expertise, and an expert in linguistics may be required for a phonetic dictionary.
E2E has been able to eliminate these disadvantages of Hybrid systems.
SR Accuracy Test
Word Error Rate (WER) is the best measurement method for comparing SR accuracies. WER is shown in (%) and is derived by comparing a reference transcript with the SR transcript for the audio. A low WER indicates a transcript with high accuracy.
WER = (substitutions + insertions + deletions) / number of words spoken
While conducting our tests, we used 1-hour Call Center records in English from 2 different industries, transcribed them into text, and calculated final word-error rates within the data set.
SESTEK has been benchmarked against major SR providers and has consistently scored the lowest WER score in this test.
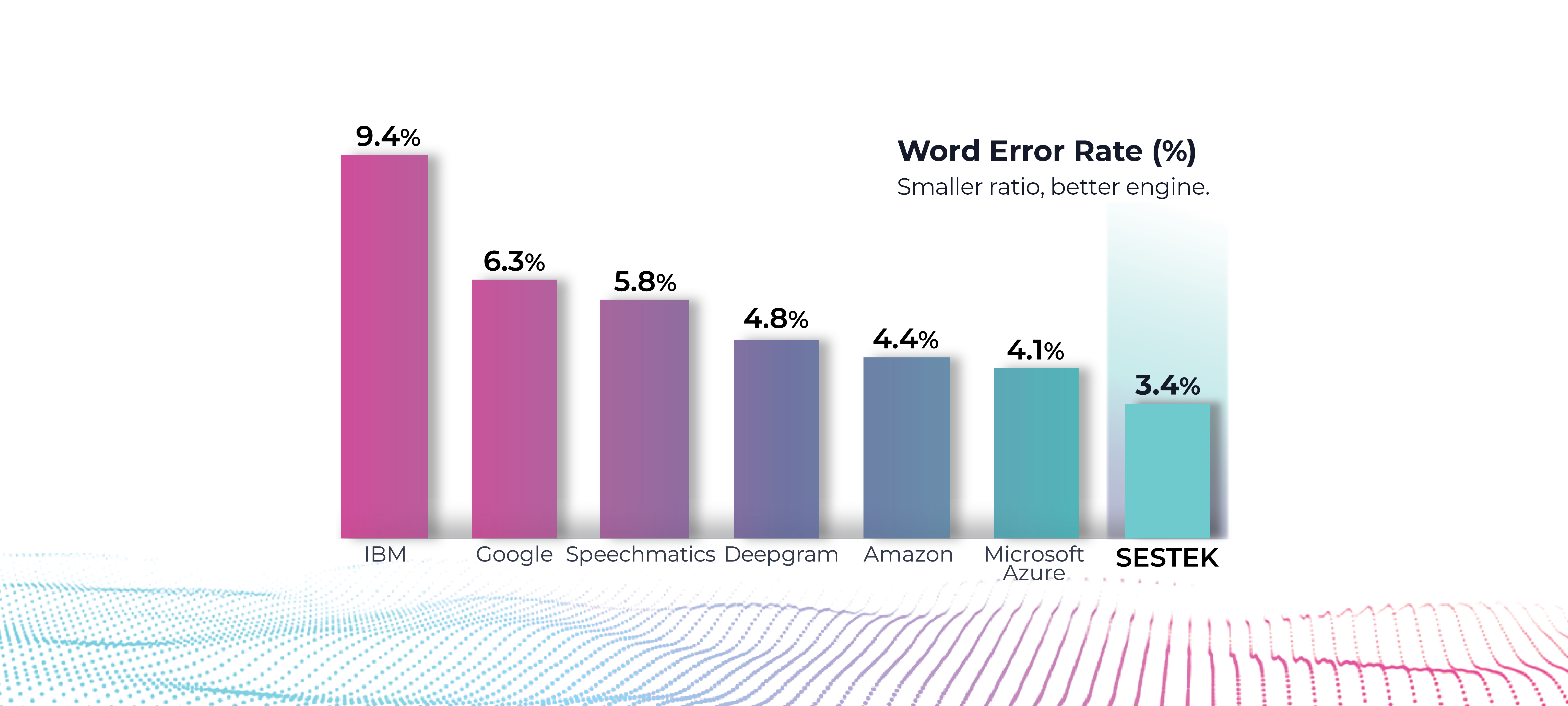
Disclaimer: Regarding the output, we are not suggesting that we are certainly better than the other vendors. The speech recognition process includes calculating and optimizing millions of parameters over a vast search space. It is hugely stochastic (a pattern that may be analyzed statistically but not predicted precisely). A vendor’s SR engine can perform better than others for a specific recording, but the same engine can perform differently for another.
Debi Çakar, Product Analyst, Product Management Team, SESTEK


