
Share
What is Speech Recognition and End-to-End Model?
Speech recognition technology, at its essence, involves translating spoken language into text. This domain has seen substantial progress throughout its evolution, propelled by innovations in artificial intelligence and machine learning. A remarkable advancement in recent years is the emergence of end-to-end (E2E) models, which have revolutionized how speech recognition systems are designed.
Traditionally, speech recognition systems relied on multiple components such as feature extraction, acoustic modeling, language modeling, and decoding. While these systems achieved impressive results, they often required significant effort to develop.
Unlike traditional systems, E2E models aim to directly map the input audio waveform to the corresponding textual output in a single step. In these models, language and acoustic models are not trained separately; instead, they are jointly learned as part of the unified architecture, facilitating seamless integration of contextual information and acoustic features during transcription.
How to Achieve High Accuracy Rate in Speech Recognition
There are several factors to be considered to achieve high accuracy in Speech Recognition systems:
- Quality of Audio Input: The clarity and quality of the audio signal significantly impact recognition accuracy. Clear audio with minimal background noise, distortion, and echoes leads to better results.
- Language Model: A robust language model tailored to the specific domain or application improves recognition accuracy. Language models capture the likelihood of word sequences and help the system decipher ambiguous speech.
- Training Data: To build accurate models, sufficient and diverse training data is necessary. The data should cover various accents, dialects, speaking styles, and environmental conditions to make the system robust.
How to Calculate the Word Error Rate (WER)
The word error rate (WER) is an assessment metric for ASR (Automatic Speech Recognition) models. It calculates the insertions, deletions and substitutions in the transcription result by comparing it to the reference text and gives a numeric result indicating the success rate of the SR accuracy. While a lower WER is preferred, it indicates a more accurate and reliable ASR model compared to a higher WER under similar conditions.

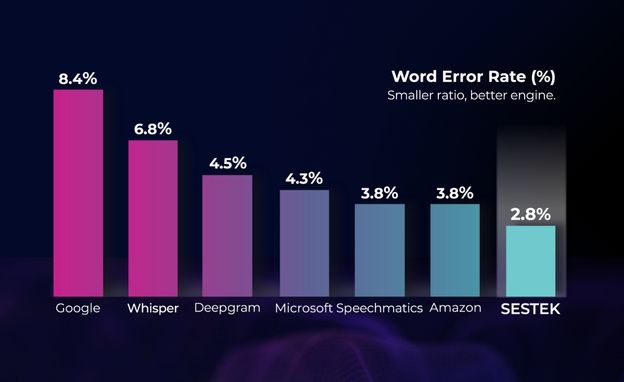
Speech Recognition Accuracy Test Results:
A mixed data set of 10hr 45min in English is used while performing the accuracy test. After transcribing the records into text, word error rates (WER) are calculated for each vendor.
SESTEK has been benchmarked against major SR providers and has consistently scored the lowest WER score in this test.
* Please find the details of the test set here.
The LibriSpeech dataset comprises around 1,000 hours of audiobooks sourced mainly from Project Gutenberg and integrated into the LibriVox project. It is organized into three training partitions of varying durations: 100 hours, 360 hours, and 500 hours. Additionally, the evaluation data is segmented into 'clean' and 'other' categories, reflecting the varying difficulty levels for Automatic Speech Recognition systems. Each of the evaluation sets, including development and testing, spans approximately 5 hours of audio content.
Disclaimer: Regarding the output, we do not suggest that we are certainly better than the other vendors. The speech recognition process includes calculating and optimizing millions of parameters over a vast search space. It is hugely stochastic (a pattern that may be analyzed statistically but not predicted precisely). A vendor’s SR engine can perform better than others for a specific recording, but the same engine can perform differently for another
Author: Şuara Atay, SESTEK Product Team



